Sharding vs Partitioning
A deep dive into the difference between sharding and partitioning in database design
Gajanan Rathod

If you’ve ever Googled **“sharding vs partitioning”** and ended up more confused than before — congrats, you’re normal.
People mix these two all the time because **both involve splitting data**, but the *how* and *why* are very different.
So let’s break it down once and for all using pizza, because engineers love splitting bills more than load.
---
First, the one-line difference (save this in cache memory 🧠)
- **Partitioning** → *Splitting one database into parts* (one pizza cut into 8 slices) - **Sharding** → *Splitting data across multiple databases / servers* (8 different pizzas)
That’s it. Everything else is just implementation details.
---
What is Database Partitioning?
Partitioning means:
> You take ONE database and split its data into multiple logical parts. >
Important things to note:
👉 **Same database**
👉 **Same server (usually)**
👉 **No horizontal scaling**
Partitioning improves **performance and manageability**, not scale.
---
Let’s understand partitioning with pizza 🍕
Imagine you are **8 people** sitting in a circle with **one pizza** 🍕.
The pizza is sliced into 8 parts, each slice facing one person.
Now everyone can eat **at the same time**.
If there was no slicing:
- Person 1 eats - Then person 2 waits - Then person 3 waits. …you get the pain.
Partitioning works the same way.
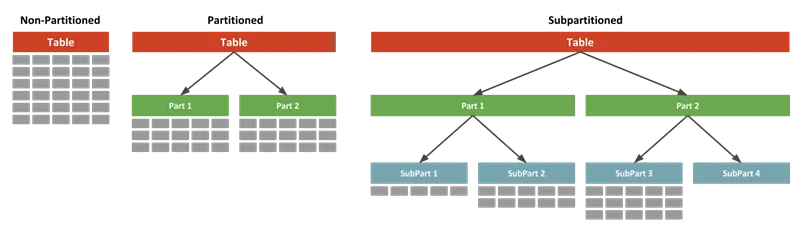
- All slices belong to the **same pizza** - You just cut it into logical parts
That’s **partitioning**.
---
Partitioning in database terms
Let’s say you have a `users` table.
You partition it by `userId`.
``` Users Table (Single DB) ├── Partition 1 → userId 1–100 ├── Partition 2 → userId 101–200 ├── Partition 3 → userId 201–300 ```
Each partition:
- Is indexed separately - Reduces scan size - Speeds up queries
If you want paneer topping info for *friend 1*,
you don’t scan the whole pizza — you check **his slice** 😌
---
Why partitioning exists
- Faster queries - Better indexing - Easier maintenance (archive or drop old partitions) - Works great **until one database hits its limits**
⚠️ **The catch**
> Partitioning does NOT help when the database server itself is overloaded. >
Ninth friend shows up.
No slices left.
Now what? 🤡
You’re still stuck with:
- One machine - One CPU - One memory limit
And that’s where **sharding** enters the chat.
---
What is Database Sharding?
Sharding means:
> You split data across multiple databases, often running on different servers. >
This is **horizontal scaling**.
---
Sharding with pizza 🍕
Ninth friend arrives.
No pizza left.
Solution?
**Order another goddamn pizza** 🍕🍕🍕
That’s horizontal scaling.
- Multiple pizzas - Each pizza has its own data - Pizzas may live at different locations
That’s **sharding**.
---
Sharding in database terms
``` Shard 1 → Users from USA Shard 2 → Users from Europe Shard 3 → Users from Asia ```
Each shard:
- Is a **separate database** - Often runs on a **separate server** - Handles its own traffic
---
How queries work in sharding (the fun part 🔥)
Let’s go back to pizza.
You’re sitting in a circle with **9 pizzas** now.
You eat the pizza **in front of you**, not the one across the table.
Unless your pizza is spoiled — then yeah, pizza chori happens 🍕👀
(That’s basically failover, but let’s not get ahead of ourselves.)
Same thing with sharding.
A request comes in:
```json { "userId": 87213, "locationId": 2 } ```
What happens?
1. App reads the **shard key** (`locationId`) 2. Routing logic decides → **Shard 2 (Europe)** 3. Query goes **directly** to that shard 4. Other shards stay chilling 😎
This is why sharding scales insanely well.
---
Partitioning vs Sharding (Side-by-Side)
| Feature | Partitioning | Sharding | |---------|--------------|----------| | Scaling type | Logical optimization | Horizontal scaling | | Number of databases | One | Multiple | | Servers | Usually one | Multiple | | Performance boost | Medium | Massive | | Complexity | Low | High | | Used when | Tables grow large | Traffic explodes |
---
When should YOU use what?
Use **Partitioning** when:
- You’re early-stage - One DB is enough - Tables are getting large - You want speed without infra pain
Use **Sharding** when:
- Traffic is crazy - One DB can’t handle load - You have global users - You want fault isolation
**Real talk:**
> Most startups don’t need sharding on day one. > > > Partition first. Shard when pain forces you to. >
---
Can you combine both?
Absolutely. Big systems do.
``` Shard (by region) └── Each shard has partitioned tables ```
Netflix, Uber, Amazon — everyone does this.
---
Final mental model (don’t forget this)
- **Partitioning** → Cutting one pizza into slices - **Sharding** → Ordering more pizzas and spreading them across the table - If your pizza is big → slice it - If no slices left → order more pizzas 🍕🍕🍕.